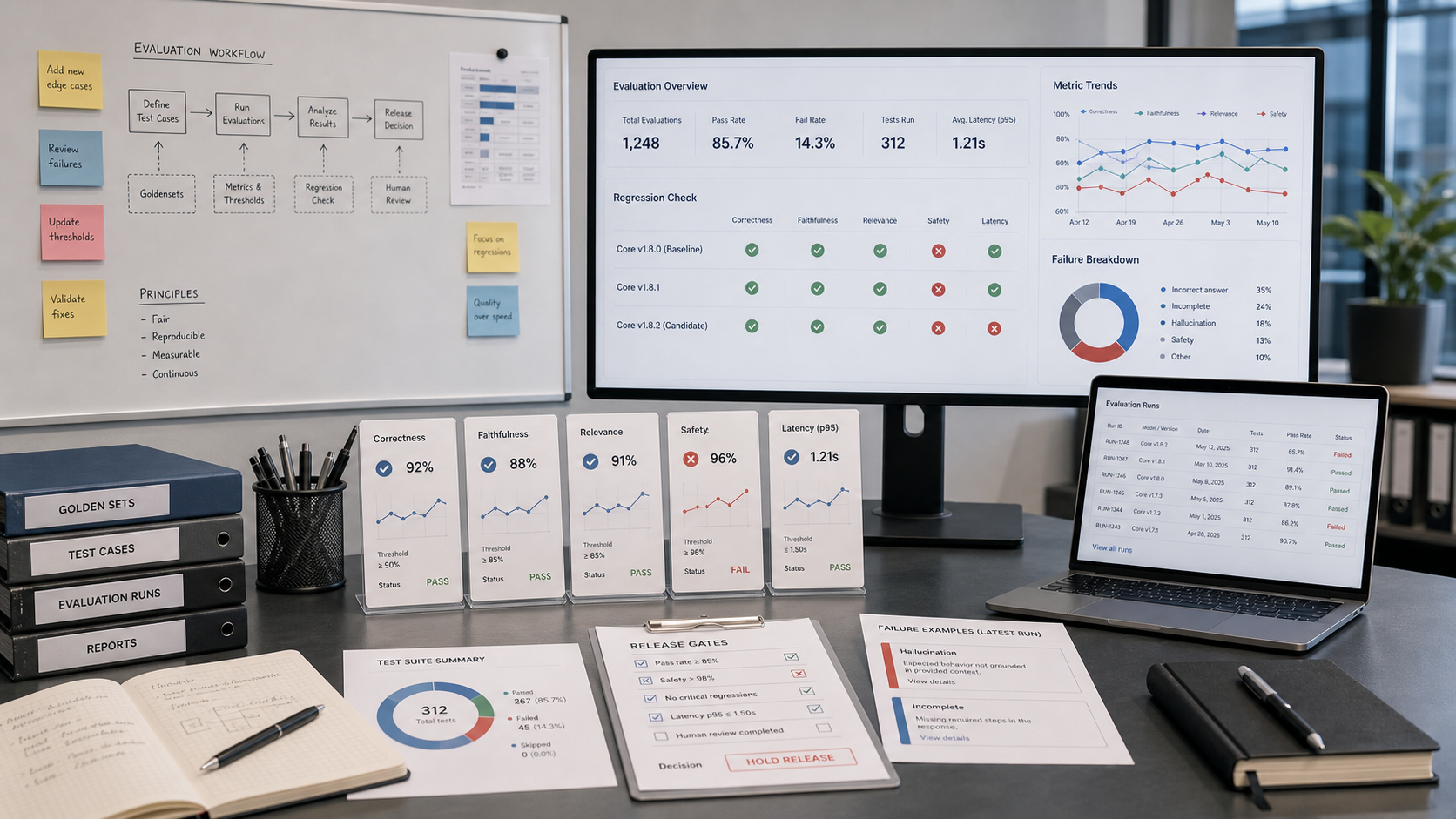
LLM-Qualitaet muss kontinuierlich getestet werden. Goldensets, Regression Tests und menschliches Feedback machen AI-Features stabil.
Executive Summary
Dieser Artikel beschreibt, wie Unternehmen den Use Case in umsetzbare Architektur,
messbare Qualitaet und robuste Delivery uebersetzen. Der Fokus liegt auf konkreten
Entscheidungen, die ein AI-Projekt produktionsfaehig machen.
100+ TestfragenRegression pro ReleaseScore nach Risikoklasse
Technical Angle
The working system for this topic is usually easier to build when the team names the first two moving parts explicitly: Goldenset and Run. That gives product, engineering, and domain experts the same mental model.
A production release should always be tied to concrete operating signals. For this article, the useful checks are 100+ Testfragen, Regression pro Release, Score nach Risikoklasse. If those numbers do not move, the feature is not yet doing real work.
The risk is rarely the headline AI feature itself. The real failure points are usually ownership, data quality, review gates, and the handoff into the existing process.
Warum Bauchgefuehl nicht reicht
Ein Prompt kann heute gut wirken und morgen durch neue Daten, Modellversionen oder Edge Cases schlechter werden. Evaluation reduziert dieses Risiko systematisch.
Goldensets aus echten Faellen
Die besten Tests kommen aus realen Tickets, Dokumenten und Fachfragen. Jede Testfrage braucht erwartete Kriterien, nicht zwingend eine wortgleiche Musterantwort.
Scorecards fuer Entscheidungen
Bewertet werden Korrektheit, Vollstaendigkeit, Quellenbezug, Tonalitaet und Risiko. Teams koennen dadurch entscheiden, ob ein Release produktionsreif ist.
Implementation Lens
A practical build sequence for LLM-Evaluation im Alltag usually starts with goldenset and run, then moves into score. That keeps the team focused on the smallest set of decisions that actually changes the outcome.
Once the first version is running, the job is to connect the feature to product operations. In this article, the relevant signals are 100+ Testfragen, Regression pro Release, Score nach Risikoklasse. Those numbers define whether the work is useful or only looks useful in a demo.
GoldensetRunScoreImprove
Common Failure Modes
The most common failure mode is not model quality. It is missing ownership, weak data hygiene, and a handoff that leaves review work outside the real process.
The second failure mode is overbuilding the interface before the workflow is understood. A thin, measurable version is better than a broad but shallow one.
Build Sequence
A strong first release for LLM-Evaluation im Alltag should stay close to the article topic: llm-evaluation im alltag. The team should define one narrow workflow, one owner, and one place where a human can review the output before anything is automated.
The sequence is usually: clarify the input, normalize the data, produce a draft or recommendation, and then expose a review step with a clear accept or edit action. That is enough to prove value without pretending the system is finished.
Only after the first slice works should the team widen the scope. At that point it becomes reasonable to add more sources, more exceptions, more automation, or a stronger model. Doing it earlier usually increases noise faster than it increases value.
Release Criteria
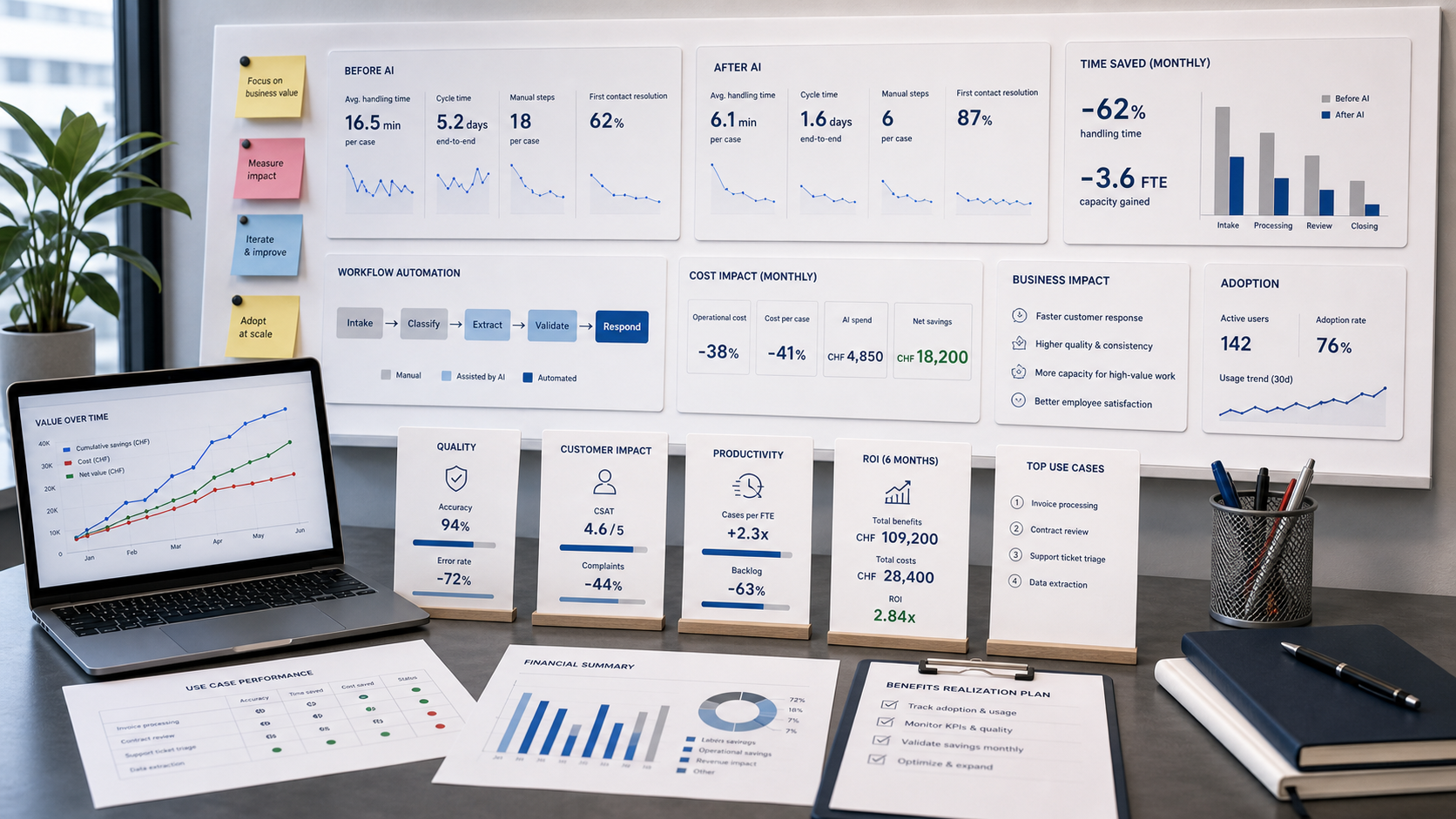
A release is ready when the team can explain what changed in business terms, not just technical terms. The product owner should be able to describe the before and after state without opening the code.
For this article, the release gate should be tied to the metrics above, plus the checklist items that matter most. If review quality, throughput, or cost are not moving in the expected direction, keep the feature in iteration.
The final check is operational: can support, product, and engineering all tell whether the system is behaving as intended? If not, observability and ownership are still incomplete.
What To Decide First
Set the first version up so it can actually ship
Testset versionieren
Kritische Faelle markieren
Automatisch pro Deployment testen
Feedback aus Produktion einspeisen
Praxis-Checkliste
Naechste sinnvolle Schritte
Testset versionieren
Kritische Faelle markieren
Automatisch pro Deployment testen
Feedback aus Produktion einspeisen
Delivery Note
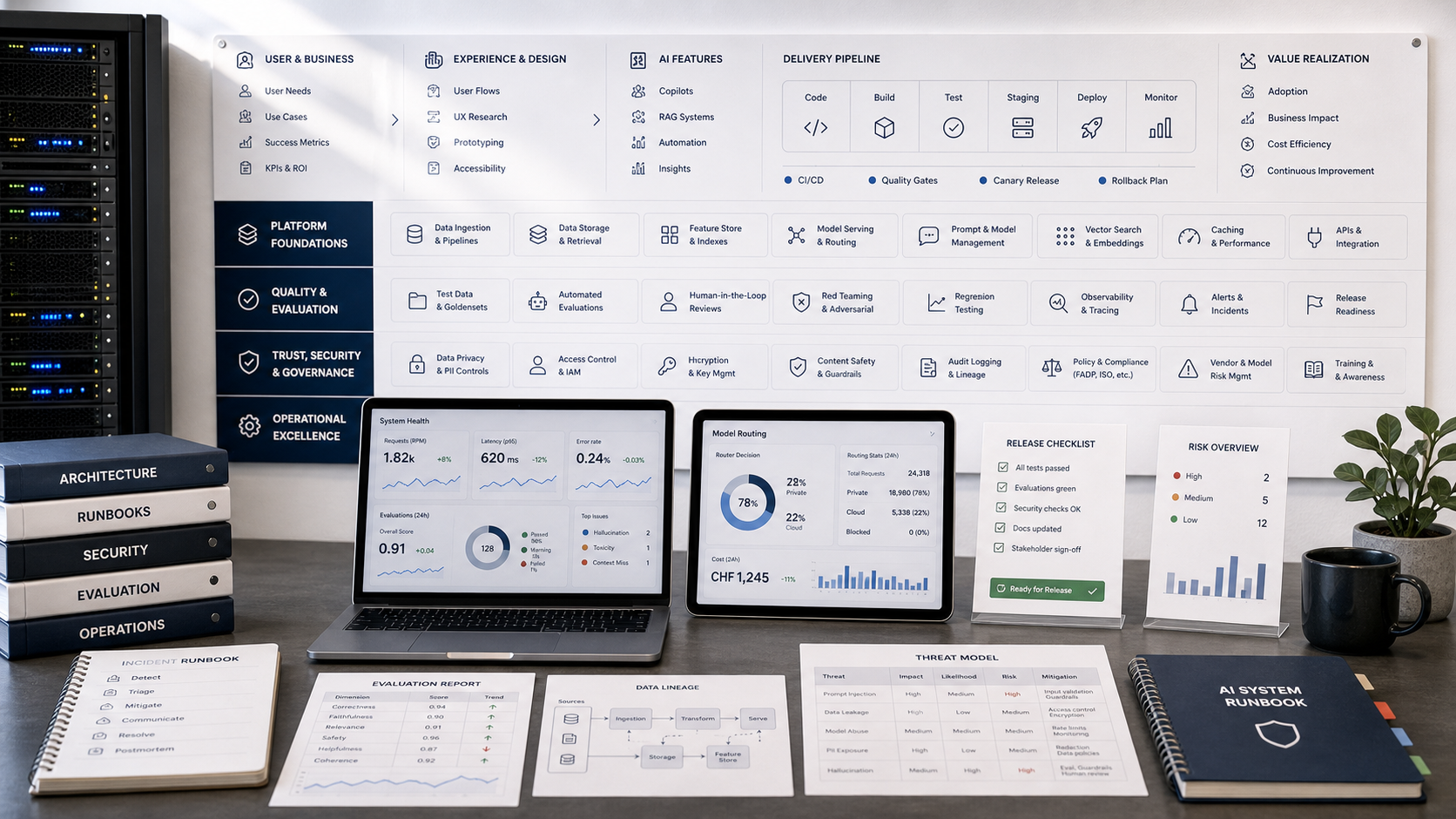
Von der Planung zur produktiven Umsetzung
AI-Projekte gewinnen erst dann an Wert, wenn Product, Data, Security, Evaluation und
Rollout als ein System betrachtet werden. Dieses Board fasst die typischen Bausteine
zusammen, die aus einer Idee eine belastbare Umsetzung machen.